最新バージョンをDLして差し替えてください。 翻訳支援ツールPCOT PCOTのソース
※今回の更新はWindows10以外のバージョンも対象です。 今回「PCOT_OTHER_WIN_10」の方はちょっと構成を変えたので動かない方はお知らせください。
今回の更新項目は1点です。 読取倍率を縮小方向にも対応しました。
今回は不具合修正1点のみです。 Google翻訳が「低品質」の状態で翻訳をしようとするとGoogle翻訳が使えない(無効状態)になってしまっていたのを修正。
今回の更新はWin10以外のバージョンをお使いの方も対象です。最新版をDLして差し替えてください。
以上です。
もう更新しないつもりだったのに・・・。
今回の更新項目は1点です。 OCRが誤読した文章を可能な限り直して翻訳します。 GoogleTranslateFreeApiはスペルミスを検知できることを思い出したので、これを使えばOCRの誤読を減らせるのではと思い、修正しました。
※Windows10以外のOSも更新対象となりますので、最新版をDLして差し替えてください。
一応、この修正を反映したソースも上げました。 「PCOTのソース」
とりあえず、翻訳する際には必ず正しいスペルに修正するようにしたので、これで誤読率が減ったんじゃないかと思います。 ただ、この修正によって新たな弊害が発生するかもしれないので、少し様子を見る必要があります。 具体的な懸念点は名詞の扱いが未知数なんです・・・。ダメそうなら戻します。
「参考画像:翻訳前」
「参考画像:翻訳後」
更新は以上です。
今回の更新項目は1つだけです。 「DeepLと連携」のチェック状態変更時にエラーが発生するのを抑制
それと、PCOTをオープンソース化しました! 「PCOTのソース」 上のリンクからDLしてください。 付属のテキストファイルを必ず読んでください!
これで最後の更新になるといいなぁ・・・。
以下に更新項目を列挙します。
暫定ですが今回がPCOTの最終バージョンとなります!つまり、PCOT1.0です! 不具合報告については今後も受け付けますが、要望対応については余ほど有意義なものでない限りは対応しません。
PCOT公開から今に至るまで応援してくださった皆様に深く感謝します! ありがとうございました!!
大分仕様も固まってきたので、今後は詳細な説明書の代わりにPCOTのFAQやTIPSなどを別トピックで掲載したいと思います。 この作業に集中するため、しばらく要望については締め切りたいと思います。 ただし、不具合報告についてはこれまで通り受け付けます。
以上、ご理解ください。
【更新内容】 システム設定画面に翻訳範囲選択時の対象プロセスを停止させるかどうかのオプションを新設しました。 「参考画像」 本項目チェック時はキャプチャー画面起動時に対象プロセスを停止させます。 逆にチェックされていない場合はキャプチャー画面が対象プロセスからフォーカスを奪うのみです。 デフォルト(リセット時)ではチェックなしの状態になっています。
今回このオプションを導入した理由は、危機回避の側面が強いです。 というのも、キャプチャー画面起動中になんらかの理由でPCOTを強制終了した場合、対象プロセスが停止したままになってしまい、復旧できなくなるためです。
なので、初めてPCOTを使う方や初めてのプロセスを選択した場合などは予期せぬ動作に備えて、予めチェックを外してからの使用を推奨します。 ただし、PCOTでフォーカスを奪っても停止しないプロセスも存在するため、安定動作が期待できる場合はチェックを入れるとポップアップの翻訳などで活躍が期待できます。 最悪チェックなしで画像翻訳という手段も取れないこともないですが、利便性は下がります。
今回の更新は以上です。
お返事が遅くなってしまい、申し訳ありませんでした。 別の方に検証して頂いたところ、普通に使えたということなのでハードウェアに依る部分が大きいのかなと思いました。 別の方の環境で動いている以上、変に対応してキーフックがバッティングして入力できなくなるとOSレベルで入力が死滅するため、対応は難しそうです。 ご不便をおかけして本当に申し訳ありません。
今回は不具合修正のみです。以下に更新項目を列挙します。
今回はWindows10以外のOSも修正対象としていますので、必ず最新版をDLして差し替えてください。
では、更新項目について以下で説明します。 【高DPI環境でレイアウトが崩れる】 今回の対応により、PCOTがぼやけて表示されますが、正常です。 何故こうなったかというと、高DPI対応しようとしても画面サイズを固定していたり、一部の固定されたコントロールは高DPI環境でスケーリングされません。 スケーリングされない画面やコントロールに対して、DPIのスケーリング倍率をベースに計算してやるか、全ての画面やコントロールをサイズ変更可能にすればとりあえずは直るんですが、ちょっと規模が大きすぎるのでやりませんでした。 代わりに、表示はぼやけますが高DPI対応を外して仮想DPIにしました。 これでレイアウトが崩れるのは直ったはずです。
【画像翻訳用の画像取得がズレる】 原因は、レイアウト表示を仮想DPIにしたことによって、PCOTで扱うサイズとその他システムで扱うサイズが変わってしまったためです。 これについては、PCOTで扱うサイズを内部的にその他システムに寄せるように計算して辻褄を合わせています。 ただ、画像翻訳用の画像は本来ならばフレームなしの画像を取得するのですが、高DPI環境だとフレームなしの画像サイズを取得する処理が上手く働かず、取得画像がズレてしまいます。 なので、高DPI環境ではフレームありの状態で画像を取得するように修正しました。 「参考画像」
上の画像の通り透明なフレーム部分が表示されてしまいます。 この点については、どうしようもなかったのでご了承願います・・・。
【ショートカットキーのデフォルト値】 これについてはデフォルトの「CTRL」だとフリー選択しようと思ったら「CTRL+F」で検索ボックスが開いてビビるという相談を頂き、それはいかんと思いよりバッティングしにくい「CTRL+SHIFT」をデフォルトにしました。
以下、私信です。 >名前なし(2e454@91076)さん とりあえず対応してみたので、お手数ですが最新版をDLして確認して頂きたいです。
最後に、この掲示板を見ている全ての方へ 書き込む際はなるべく「名前なし」を避けて頂きたいです。トリップで一応個人の判別はできますが、私信を出しづらいので、他の方となるべく名前が被らないコテハンで書き込んでください。お願いします。
おぉ、検証ありがとうございます! でも・・・全然原因が思いつきません・・・。 というのも、他の方からWIN7での動作報告を受けていますが、普通に翻訳まで行えるようです。 PCOT_OTHER_WIN10を作ったのもそれがきっかけなんですが、片方で動いてもう片方では動かない原因は環境由来な気がするんですが、C2Tの言語データで動く理由が分からないです・・・。
一応、こちらでも原因を調査してみます。 そして、そちらの問題はとりあえずは解決したと思ってもいいんですよね?
最後に、とても良いヒントを頂けました。今後の参考にさせて頂きます。 ありがとうございました。
お返事ありがとうございます。ランタイムはインストールされておりますが、やはりダメなようです。 原因の切り分けの参考になるかわかりませんが、Capture2Textは問題なく使用できております。
追記です。試しにCapture2Textのtessdataフォルダ内のファイルeng.traineddataをコピーし 本ツールの同名ファイルと置き換えたところ、応答停止が起こらず読み取れ使用可能でした。
PCOTをご使用いただき、ありがとうございます。
状況から察するに、OCRが対応していないようです。 PCOTのOCRは「Tesseract OCR」というものを使用していますが、ランタイムがインストールされていないと動作しません。
Visual Studio 2015 の Visual C++ 再頒布可能パッケージ 上記のリンクから「vc_redist.x86.exe」をDLしてインストールしてみてください。
上記をインストールした上で動作しないという場合は、作者環境で再現できないため、申し訳ありませんがWIN7には対応できないと思います。
初めまして。 不具合を確認してみました。結果、こちらでも再現できました。 スケーリング設定については、かなり前に指摘を受けて対応したんですが(OCRが正常に出来ているみたいなので対応自体は出来ていると思います) 問題はレイアウトがズレてしまうことで、これの直し方がイマイチ分かっていません。 スケーリングを弄った状態で正しい配置にしたとしても、今度はスケーリングを弄ってない状態で配置がズレる可能性もあり・・・ちょっと色々と調査が必要です。 申し訳ありませんが、少しお時間ください。 結果、もし対応できなかった場合は本当に申し訳ありませんがDPIのスケーリングには非対応とさせて頂くかも知れません。 でも、出来る限り努力はします。
Windows7環境ですが、OCR翻訳を試みると本ツールが応答を停止して落ちてしまいます。 原文枠に手打ちして即時翻訳を試みる分には問題ありませんでした。
ダウンロードしてPCOT_OTHER_WIN10.exeをPCOT.exeにリネームしただけのほぼ初期状態です。
初めまして。ゲームの翻訳ツールと聞いて触らせていただきました。 固定領域の翻訳がありがたいです。。
ただ触ったところWindows10のスケーリング上書きがOCRに影響をあたえているようでしたので、確認してもらえますでしょうか。
4Kディスプレイを使用しており、Windowsのスケーリング設定を150%にしているのですが、 PCOTの画面レイアウトが崩れてしまい、ショートカット設定画面などは、リセット/閉じるボタンが画面外に出てしまい、ボタンが押せず閉じれなくなってしまいました。 アプリケーション個別でスケーリング設定を変更できるようでしたので、PCOT.exeのプロパティ、高DPIスケール設定の上書きにシステムを選択することで、正常な画面レイアウトでPCOTを起動させることができました。 が、この状態ではOCR機能の領域設定がうまくいかない(赤字でOCR読み込み失敗が表示される)ようになってしまいました。(OCR領域xyがおかしくなる??)
現状はスケーリング設定を切り替えながら使わせていただいてます。よろしくお願いします。
今後の予定として、ゲーミングマウスのショートカット対応とやっぱり説明書作るのは大変そうなので、FAQとTIPSにそれぞれトピック作って解説することにします。というか、そうさせてください・・・。
ありがとうございます。そういって頂けると助かります。 ご存じの通り、システムの仕様変更については既存の部分の作り直しが発生するため、他への影響範囲を考えるとご期待に添えない場合も多いかと思いますが、機能追加の方面であればあまり無茶な要望でなければ実現できる可能性は高まると思います。(それでも完全に要望通りとはいかないかもしれませんが)
なので、また何かありましたらお気軽にお問合せください。
一考していただけるだけでも十分に感謝です。 あくまで使ってみて「こうだと良いなぁ」って思いつきを共有したかったのでダメならダメで大丈夫です。 プログラミングやソフトウェア開発の難しさは知ってます。 現状でも十分ありがたいソフトです。
返信ありがとうございます。 まず、新たなご要望の件についてですが
>1画面の場合翻訳結果が見れなくなる関係上 それもありますが、ゲームによってはOCRの精度が悪く、読取倍率を変えてみたり辞書(名詞)登録が発生したりするのでPCOTに戻ってきた方がいい場合もあるのと、DeepLと自動で連携をした場合にDeepLが外部アプリなので現在のフォーカス状態をPCOT側で正確に把握できないのです。 加えて、既存の仕様をひっくり返す修正になるので、工数がかかるのと修正後の動作が不安定になり易いです。 なので、この修正については見送らせてください。申し訳ありません。
重ねて申し訳ないのですが・・・最初の修正についても調査した結果、同じく既存の仕様をひっくり返す修正になるのでそれなりに工数がかかるのと、よしんば修正したとしても他のユーザーから不満が出ると困るので他のユーザーの声も聞きたいと思います。 その結果不便を強いることになってしまう場合もありますので、予めご了承願います。
丁寧な返信ありがとうございます。 個人的に処理の遅さよりも1度画面が消える事に少なからず目の疲れを感じていたので、消えないようになるだけで大助かりです。 それと、これも可能であればで良いんですが翻訳完了した後、ウィンドウの選択がPOCTではなくゲームの方に戻ってもらえると助かるな、と。 こちらも1画面の場合翻訳結果が見れなくなる関係上、だと思うのですが、ウィンドウを手動で切り替える手間を省けるのでご一考お願いします。
すみません、それともう一つ。 PCOTのレスポンスについてなんですが、開発言語(C#)の特性的に初回は反応が遅くなりがちなのと、他にレスポンスが遅い要因として、PCOTが前述の様に対象プロセスのフォーカスを奪う処理を挟んでいるためです。これについては、必須機能なので外せません。 もしCapture2Textよりも遅いと思われていたとしたら、上記の理由に加えて開発言語の違いもあると思います。 Capture2TextはC++で開発されていますが、PCOTはC#なので普通に組むとどうしても速度に差が出てしまいます。
そういう意味では、もし今回の対応を施したとしても思った以上の速度改善は見込めないかも知れないです。
以上のことをご理解頂けると幸いです。
こちらこそはじめまして。 ご要望の件についてなんですが、元々PCOTのウィンドウを消しているのはキャプチャー画面起動中に翻訳表示画面を触れなくするのが目的でした。 なので対応するとしたらオプション項目を増やすのではなく、キャプチャー画面起動中は翻訳表示画面を触れなくするといった感じになるかな、と感じました。 これであれば、単一画面でもPCOTがフォーカスを奪うため、プロセスが最前面に表示される筈なのでどちらの場合でも邪魔にならないと思いますが、それでもよろしいですか?
はじめまして 私は2画面でサブの方にPCOTを置いて、メイン画面でゲームをしつつ利用しているのですが、画面を選択する時にPCOTのウィンドウが一旦消えるのが気になりました。 1画面だと大変ありがたい仕様ですが、サブに置いて一旦消えなくても良い場合このワンクッションは処理の遅延に繋がってないかなと感じたので、出来ればウィンドウを一旦非表示にする設定を切り替えられるようになったらいいなと思いました。
ショートカットの多ボタンマウス対応、前向きにご検討いただけるようで嬉しく思います。 PCOTのさらなる発展を楽しみに、引き続きこちらのページ、またTwitterの方も見させていただきます。
検証ありがとうございます。 なるほど、Capture2Textはその辺ちゃんと対応されているんですね。 すぐには無理ですが、一度対応してみようと思います。
なので、お手数ですが時々ここをチェックして頂けると幸いです。 もしTwitterをやっていたら、いつも近況報告をしているので、フォローして頂けるとこちらの動向が掴みやすいかもしれません。
迅速かつ丁寧なご説明ありがとうございます。
あくまで推測として、PCOT側の入力信号の優先順位や支配処理が原因なのでは?と理解いたしました。 ゲームパッドのボタンに割り当てて使う分には問題がないので「PCOT側ではショートカットと判断する前に マウス入力として切り捨てられている」というご説明はとてもわかりやすく、素人の私でも理解できました。 もちろんPCOTと私が使用しているマウスとの個別の相性、またはマウス側の問題の可能性も考えられますが。
「Capture2Textではマウスからのショートカットに対応しているのでしょうか?」についてですが Capture2Textではマウスのサイドボタンによるショートカット入力も問題なく使用できております。 具体的にはマウスの左側、右手持ちで親指が当たる側面部分にボタンが2つ並んでいるマウスなのですが、 そのボタンにショートカットキー(Capture2Textではhotkeys)を割り当てる、といった使い方です。
もし原因が推測通りなのであれば、誠に勝手ながらPCOTのさらなる発展を心より願っております。
こちらこそはじめまして。PCOTをご使用頂き、ありがとうございます。
ご指摘の件についてですが、当方がゲーミングマウスを所有していないため、全て推測になってしまうことを予めご留意願います。
推測される原因についてですが・・・ 恐らく、システム側では最終的にショートカットとして認識していると思われますが、PCOT側ではショートカットと判断する前にマウス入力として切り捨てられているのかも知れません。
対応についてですが、もし私の推測が正しかった場合はPCOTの実装に問題があるので、PCOTを修正すれば対応できるかも知れませんが、先に書いた通り当方がゲーミングマウスを所有していないため、マウス入力の内容を精査できないんです・・・。
ちなみに、Capture2Textではマウスからのショートカットに対応しているのでしょうか? もし試せるようでしたらご回答いただけると幸いです。
あまりお役に立てず申し訳ありません・・・。
はじめまして。 PCOT、英語が苦手ながら洋ゲーが好きな自分はとてもありがたく思いながら使わせていただいております。
ショートカットについて。ショートカットをゲームパッド+joytokeyで使用するには問題なく使えるのですが、 5ボタンマウスのサイドボタンに割り当てて使おうとしても無反応になります。(【フリー選択】が出来ない)
マウスのサイドボタンでショートカット(例えばCTRL+Fなど)が押されているのか、キーボードテストなどで 確認してみましたが、ショートカット(CTRL+F)は間違いなく押され、信号は送られているようでした。
つたない文章で状況を正確にお伝えできてるか不安ですが、この「マウスのサイドボタンでショートカットが 使えない(無反応)」の症状について、推測される原因や解決策などございましたらご教授いただければ幸いです。
※ゲームパッドやキーボードではまったく問題なく使わせていただいております。ありがとうございます。
今回の更新も1点のみです。 Windows10以外のOSにも対応してみました。
Twitterの方でWin7の動作報告を頂けたので、それに合わせて修正してみました。 ご使用方法は以下の画像をご覧ください。
以上です。 これで動くといいなぁ・・・。
PCOTを更新しました!一度こういう痛い煽り文句付けてみたかったんですよねw
今回の更新は1点のみです。 PCOTが「Windows10 OCR」に対応しました!尚、以下の点を注意してご使用ください。
尚、使用OCRエンジンの選択は「システム設定画面」から行えます。 「参考画像」
Windows言語パック(英語)のインストール方法
以上です!動かないよーって方が居ましたら、お気軽にお問い合わせください。
更新項目を以下に列挙します。
更新項目についての説明です。 【関係ないショートカット】 画像翻訳画面でSHIFT+ENTERなどを押すと、DeepLが反応しなくなったりしますがこれで今回の修正で直っている筈です。
【画像翻訳の画像ファイルの読取方法を変更】 時々、画像翻訳のファイルが削除できなかったので、画像ファイルの読取方法を変更しました。これで、プロセスがどうたら怒られずに画像ファイルを削除できる筈です。
【画像翻訳で大文字小文字が違うだけのプロセス起動時のSS失敗】 プロセス名が「Game」と「game」で違うプロセスだったとしても、ファイルパスは大文字小文字を区別しないため、同列と扱われますが、既存の画像ファイル名を文字列として扱うとエラーになってしまっていたため、画像翻訳については修正しました。(※他に同様の理由で不具合を起こす箇所があるかもしれません)
【キャプチャー画面起動時に対象プロセスのスレッドを停止】 今回の更新の目玉はこれです。地味ですがとても使える機能だと思います。 ゲームの種類によってはキャプチャー画面でフォーカスを奪ったとしてもポップアップが消えてしまったりするのを防止します・・・たぶん。
今回の更新は大したことはありません。 更新項目としては、画像翻訳で←→キーの他にADキーで画像を切り替えられるように修正しました。あと、あまりにも拡大縮小の動きがもっさりしていたので、拡大/縮小の単位を若干上げました。
以上です。これくらいの更新だったら楽でいいなぁ・・・。
久々の更新です。以下に更新内容を列挙します。
【「翻訳結果をコピー」のチェック状態が記憶されない】 そのままです。ポカミスです・・・。直しました。
【スクロールキャプチャー機能追加】 洋ゲーで「キャラクターのセリフが勝手にスクロールして翻訳できない!」といった問題をなんとかしたくて追加した機能です。
先に注意事項を列挙しておきます。
<使用方法>
更新は以上です。細かい不具合があるかも知れないので、もし変な動きをした場合はお知らせください。 以上です。めっちゃ疲れた・・・。
今回は悲しいお知らせです・・・。 やはり翻訳精度を上げたせいか、無制限の使用が出来なくなってしまったようです・・・。 ただ、一度ブラウザと同じ精度で翻訳されるのに慣れてしまったせいか、どうしても元に戻すのが嫌だったので、弾かれた場合に元の無制限で使用できるバージョンに切り替えるように対応しました。 その際、使用している最中に突然アホな翻訳になってしまうので、今がどっちの状態かをステータス領域にて可視化させることにしました。
「参考画像」 ※インターネット接続が切れている場合などは、プロセスの切断と同じカラー構成で「Google翻訳:無効」と表示されるようになっています。
ステータスの可視化は、プロセス選択時に一度ダミーの翻訳を投げてレスポンスの状態で表示を切り替えているので、プロセス選択はあまり頻繁に行わないよう推奨します。たかが一回、されど一回ですw
というわけで、今回はガッカリな更新になってしまいました・・・。
更新項目について説明します。
【画像のローテーション表示】 左右キーで画像の表示をローテーションさせるように修正しました。 例)画像が3枚ある場合 「→キー」画像1→画像2→画像3→画像1 「←キー」画像1←画像3←画像2←画像1
【画像翻訳をショートカットで起動】 ショートカットが有効な状態で、翻訳表示画面起動中に「ベースキー」+「I」で画像翻訳画面を起動します。
☆注意☆ ショートカットの設定ファイルの内容が変わりますので、ショートカット設定画面を表示後、一度リセットして今回の更新を適用する必要があります。
【改行無視の修正】 「改行を無視」の実装により「対象通りに改行」と被らないように実装したつもりでしたが、色々とイベントが入り乱れて変なことになってたので修正しました。
【訳文で文字選択中に別のコントロールクリックするとエラー】 翻訳表示画面のサイズを変更できるようにした際に組み込んでしまったバグです。これで直っているハズ。
【辞書登録と名詞登録時の警告を削除】 原文を小文字化にチェックがあったとき、警告で大文字小文字が合ってないけど大丈夫ですか?みたいな警告を出してたんですが、今はもう不要なので削除しました。
なんか、普通にショートカットが実装できちゃったので今回の更新にまとめます。
お久しぶりです!すみません、結局実装しちゃいましたw
ただ、簡易コマンドも悪いものではないので残してあります。 たとえば、ゲーム上で何かキーボードのボタンが押されたら勝手に会話が進んじゃうようなゲームの場合は、ショートカットでキャプチャーを行うのが不可能なんですよね。(たとえアクティブじゃなくても)
後は、最近画像翻訳という機能も実装したので、そちらも使ってみてください。 詳しい説明を以下に貼っておきます。 画像翻訳説明1 画像翻訳説明2
作者の励みになりますので、また色々と感想とか要望とかくださいね! あと、周りの人にも沢山広めてください!お願いします!
お久しぶりです。なんと見ていなかったうちにショートカットが実装されていたとは…。ゲームによっては簡易コマンドの切り替えがうまくいかないものがあったので、やっぱりショートカットもあればな…と思っていたのでとても嬉しいです。遅くなりましたが実装ありがとうございます!
今回は一か所だけ更新しました。 「翻訳表示画面」の「原文を小文字化」のチェックボックスを廃止 代わりに、「改行を無視」のチェックボックスに変更 ちなみに、この「改行を無視」は領域単位でチェック状態を保存しています。(フリー選択を除く)
何がどう変わったかを一目で分かるようにまとめた画像を以下に貼りましたので参照してください。 注:画像は英語で長い文章をつくるコツ!から拝借しました。
「原文を小文字化」を廃止した理由として、現在PCOTでは大文字小文字を自動的に判断して適宜変換するような処理を行っています。 例1)文章が全て大文字の場合は全て小文字に変換 処理前:I AM A PEN. 処理後:i am a pen.
例2)文章が強調表示などで単語単位で大文字の場合は小文字に変換(IやAなどの1文字だけ大文字の場合は除外) 処理前:I am a PEN. 処理後:I am a pen.
例3)単語単位で先頭以外の不自然な場所に大文字がある場合は単語単位で小文字に変換(OCR読取失敗対策) 処理前:TEST Test teSt tesT 処理後:test Test test test
前は上記の処理を行っていなかったため、一律「原文を小文字化」というチェックでごまかしていましたが、上記の処理をするようにしたので、もう要らないだろうということで廃止しました。
問題なさそうでよかったです。 こちらでも色々と試してますが、もし何かあった場合はお気軽にお問合せください。
素早い更新、ありがとうございます。 さっそく頂きました。 ためしたところ、問題なさそうです。
しばらく、これで試してみますね。

PCOTを更新しました。
最新バージョンをDLして差し替えてください。
翻訳支援ツールPCOT
PCOTのソース
※今回の更新はWindows10以外のバージョンも対象です。
今回「PCOT_OTHER_WIN_10」の方はちょっと構成を変えたので動かない方はお知らせください。
今回の更新項目は1点です。
読取倍率を縮小方向にも対応しました。
翻訳対象の文字が大きすぎる場合に縮小倍率で設定すると読取精度が向上する可能性があります。
PCOTを更新しました。
今回は不具合修正1点のみです。
Google翻訳が「低品質」の状態で翻訳をしようとするとGoogle翻訳が使えない(無効状態)になってしまっていたのを修正。
今回の更新はWin10以外のバージョンをお使いの方も対象です。最新版をDLして差し替えてください。
以上です。
PCOTを更新しました・・・。
もう更新しないつもりだったのに・・・。
今回の更新項目は1点です。
OCRが誤読した文章を可能な限り直して翻訳します。
GoogleTranslateFreeApiはスペルミスを検知できることを思い出したので、これを使えばOCRの誤読を減らせるのではと思い、修正しました。
※Windows10以外のOSも更新対象となりますので、最新版をDLして差し替えてください。
一応、この修正を反映したソースも上げました。
「PCOTのソース」
とりあえず、翻訳する際には必ず正しいスペルに修正するようにしたので、これで誤読率が減ったんじゃないかと思います。
ただ、この修正によって新たな弊害が発生するかもしれないので、少し様子を見る必要があります。
具体的な懸念点は名詞の扱いが未知数なんです・・・。ダメそうなら戻します。
「参考画像:翻訳前」
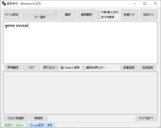
「参考画像:翻訳後」
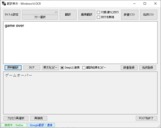
更新は以上です。
PCOTを更新しました。
今回の更新項目は1つだけです。
「DeepLと連携」のチェック状態変更時にエラーが発生するのを抑制
それと、PCOTをオープンソース化しました!
「PCOTのソース」
上のリンクからDLしてください。
付属のテキストファイルを必ず読んでください!
これで最後の更新になるといいなぁ・・・。
PCOTが完成しました!
以下に更新項目を列挙します。
暫定ですが今回がPCOTの最終バージョンとなります!つまり、PCOT1.0です!
不具合報告については今後も受け付けますが、要望対応については余ほど有意義なものでない限りは対応しません。
PCOT公開から今に至るまで応援してくださった皆様に深く感謝します!
ありがとうございました!!
【告知】
大分仕様も固まってきたので、今後は詳細な説明書の代わりにPCOTのFAQやTIPSなどを別トピックで掲載したいと思います。
この作業に集中するため、しばらく要望については締め切りたいと思います。
ただし、不具合報告についてはこれまで通り受け付けます。
以上、ご理解ください。
PCOTを更新しました。
【更新内容】
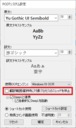
システム設定画面に翻訳範囲選択時の対象プロセスを停止させるかどうかのオプションを新設しました。
「参考画像」
本項目チェック時はキャプチャー画面起動時に対象プロセスを停止させます。
逆にチェックされていない場合はキャプチャー画面が対象プロセスからフォーカスを奪うのみです。
デフォルト(リセット時)ではチェックなしの状態になっています。
今回このオプションを導入した理由は、危機回避の側面が強いです。
というのも、キャプチャー画面起動中になんらかの理由でPCOTを強制終了した場合、対象プロセスが停止したままになってしまい、復旧できなくなるためです。
なので、初めてPCOTを使う方や初めてのプロセスを選択した場合などは予期せぬ動作に備えて、予めチェックを外してからの使用を推奨します。
ただし、PCOTでフォーカスを奪っても停止しないプロセスも存在するため、安定動作が期待できる場合はチェックを入れるとポップアップの翻訳などで活躍が期待できます。
最悪チェックなしで画像翻訳という手段も取れないこともないですが、利便性は下がります。
今回の更新は以上です。
お返事が遅くなってしまい、申し訳ありませんでした。
別の方に検証して頂いたところ、普通に使えたということなのでハードウェアに依る部分が大きいのかなと思いました。
別の方の環境で動いている以上、変に対応してキーフックがバッティングして入力できなくなるとOSレベルで入力が死滅するため、対応は難しそうです。
ご不便をおかけして本当に申し訳ありません。
PCOTを更新しました。
今回は不具合修正のみです。以下に更新項目を列挙します。
今回はWindows10以外のOSも修正対象としていますので、必ず最新版をDLして差し替えてください。
では、更新項目について以下で説明します。
【高DPI環境でレイアウトが崩れる】
今回の対応により、PCOTがぼやけて表示されますが、正常です。
何故こうなったかというと、高DPI対応しようとしても画面サイズを固定していたり、一部の固定されたコントロールは高DPI環境でスケーリングされません。
スケーリングされない画面やコントロールに対して、DPIのスケーリング倍率をベースに計算してやるか、全ての画面やコントロールをサイズ変更可能にすればとりあえずは直るんですが、ちょっと規模が大きすぎるのでやりませんでした。
代わりに、表示はぼやけますが高DPI対応を外して仮想DPIにしました。
これでレイアウトが崩れるのは直ったはずです。
【画像翻訳用の画像取得がズレる】
原因は、レイアウト表示を仮想DPIにしたことによって、PCOTで扱うサイズとその他システムで扱うサイズが変わってしまったためです。
これについては、PCOTで扱うサイズを内部的にその他システムに寄せるように計算して辻褄を合わせています。
ただ、画像翻訳用の画像は本来ならばフレームなしの画像を取得するのですが、高DPI環境だとフレームなしの画像サイズを取得する処理が上手く働かず、取得画像がズレてしまいます。
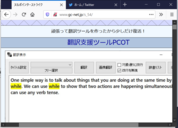
なので、高DPI環境ではフレームありの状態で画像を取得するように修正しました。
「参考画像」
上の画像の通り透明なフレーム部分が表示されてしまいます。
この点については、どうしようもなかったのでご了承願います・・・。
【ショートカットキーのデフォルト値】
これについてはデフォルトの「CTRL」だとフリー選択しようと思ったら「CTRL+F」で検索ボックスが開いてビビるという相談を頂き、それはいかんと思いよりバッティングしにくい「CTRL+SHIFT」をデフォルトにしました。
以下、私信です。
>名前なし(2e454@91076)さん
とりあえず対応してみたので、お手数ですが最新版をDLして確認して頂きたいです。
最後に、この掲示板を見ている全ての方へ
書き込む際はなるべく「名前なし」を避けて頂きたいです。トリップで一応個人の判別はできますが、私信を出しづらいので、他の方となるべく名前が被らないコテハンで書き込んでください。お願いします。
おぉ、検証ありがとうございます!
でも・・・全然原因が思いつきません・・・。
というのも、他の方からWIN7での動作報告を受けていますが、普通に翻訳まで行えるようです。
PCOT_OTHER_WIN10を作ったのもそれがきっかけなんですが、片方で動いてもう片方では動かない原因は環境由来な気がするんですが、C2Tの言語データで動く理由が分からないです・・・。
一応、こちらでも原因を調査してみます。
そして、そちらの問題はとりあえずは解決したと思ってもいいんですよね?
最後に、とても良いヒントを頂けました。今後の参考にさせて頂きます。
ありがとうございました。
お返事ありがとうございます。ランタイムはインストールされておりますが、やはりダメなようです。
原因の切り分けの参考になるかわかりませんが、Capture2Textは問題なく使用できております。
追記です。試しにCapture2Textのtessdataフォルダ内のファイルeng.traineddataをコピーし
本ツールの同名ファイルと置き換えたところ、応答停止が起こらず読み取れ使用可能でした。
PCOTをご使用いただき、ありがとうございます。
状況から察するに、OCRが対応していないようです。
PCOTのOCRは「Tesseract OCR」というものを使用していますが、ランタイムがインストールされていないと動作しません。
Visual Studio 2015 の Visual C++ 再頒布可能パッケージ
上記のリンクから「vc_redist.x86.exe」をDLしてインストールしてみてください。
上記をインストールした上で動作しないという場合は、作者環境で再現できないため、申し訳ありませんがWIN7には対応できないと思います。
初めまして。
不具合を確認してみました。結果、こちらでも再現できました。
スケーリング設定については、かなり前に指摘を受けて対応したんですが(OCRが正常に出来ているみたいなので対応自体は出来ていると思います)
問題はレイアウトがズレてしまうことで、これの直し方がイマイチ分かっていません。
スケーリングを弄った状態で正しい配置にしたとしても、今度はスケーリングを弄ってない状態で配置がズレる可能性もあり・・・ちょっと色々と調査が必要です。
申し訳ありませんが、少しお時間ください。
結果、もし対応できなかった場合は本当に申し訳ありませんがDPIのスケーリングには非対応とさせて頂くかも知れません。
でも、出来る限り努力はします。
Windows7環境ですが、OCR翻訳を試みると本ツールが応答を停止して落ちてしまいます。
原文枠に手打ちして即時翻訳を試みる分には問題ありませんでした。
ダウンロードしてPCOT_OTHER_WIN10.exeをPCOT.exeにリネームしただけのほぼ初期状態です。
初めまして。ゲームの翻訳ツールと聞いて触らせていただきました。
固定領域の翻訳がありがたいです。。
ただ触ったところWindows10のスケーリング上書きがOCRに影響をあたえているようでしたので、確認してもらえますでしょうか。
4Kディスプレイを使用しており、Windowsのスケーリング設定を150%にしているのですが、
PCOTの画面レイアウトが崩れてしまい、ショートカット設定画面などは、リセット/閉じるボタンが画面外に出てしまい、ボタンが押せず閉じれなくなってしまいました。
アプリケーション個別でスケーリング設定を変更できるようでしたので、PCOT.exeのプロパティ、高DPIスケール設定の上書きにシステムを選択することで、正常な画面レイアウトでPCOTを起動させることができました。
が、この状態ではOCR機能の領域設定がうまくいかない(赤字でOCR読み込み失敗が表示される)ようになってしまいました。(OCR領域xyがおかしくなる??)
現状はスケーリング設定を切り替えながら使わせていただいてます。よろしくお願いします。
PCOTを更新しました。
以下に更新項目を列挙します。
更新は以上です。
今後の予定として、ゲーミングマウスのショートカット対応とやっぱり説明書作るのは大変そうなので、FAQとTIPSにそれぞれトピック作って解説することにします。というか、そうさせてください・・・。
ありがとうございます。そういって頂けると助かります。
ご存じの通り、システムの仕様変更については既存の部分の作り直しが発生するため、他への影響範囲を考えるとご期待に添えない場合も多いかと思いますが、機能追加の方面であればあまり無茶な要望でなければ実現できる可能性は高まると思います。(それでも完全に要望通りとはいかないかもしれませんが)
なので、また何かありましたらお気軽にお問合せください。
一考していただけるだけでも十分に感謝です。
あくまで使ってみて「こうだと良いなぁ」って思いつきを共有したかったのでダメならダメで大丈夫です。
プログラミングやソフトウェア開発の難しさは知ってます。
現状でも十分ありがたいソフトです。
返信ありがとうございます。
まず、新たなご要望の件についてですが
>1画面の場合翻訳結果が見れなくなる関係上
それもありますが、ゲームによってはOCRの精度が悪く、読取倍率を変えてみたり辞書(名詞)登録が発生したりするのでPCOTに戻ってきた方がいい場合もあるのと、DeepLと自動で連携をした場合にDeepLが外部アプリなので現在のフォーカス状態をPCOT側で正確に把握できないのです。
加えて、既存の仕様をひっくり返す修正になるので、工数がかかるのと修正後の動作が不安定になり易いです。
なので、この修正については見送らせてください。申し訳ありません。
重ねて申し訳ないのですが・・・最初の修正についても調査した結果、同じく既存の仕様をひっくり返す修正になるのでそれなりに工数がかかるのと、よしんば修正したとしても他のユーザーから不満が出ると困るので他のユーザーの声も聞きたいと思います。
その結果不便を強いることになってしまう場合もありますので、予めご了承願います。
丁寧な返信ありがとうございます。
個人的に処理の遅さよりも1度画面が消える事に少なからず目の疲れを感じていたので、消えないようになるだけで大助かりです。
それと、これも可能であればで良いんですが翻訳完了した後、ウィンドウの選択がPOCTではなくゲームの方に戻ってもらえると助かるな、と。
こちらも1画面の場合翻訳結果が見れなくなる関係上、だと思うのですが、ウィンドウを手動で切り替える手間を省けるのでご一考お願いします。
すみません、それともう一つ。
PCOTのレスポンスについてなんですが、開発言語(C#)の特性的に初回は反応が遅くなりがちなのと、他にレスポンスが遅い要因として、PCOTが前述の様に対象プロセスのフォーカスを奪う処理を挟んでいるためです。これについては、必須機能なので外せません。
もしCapture2Textよりも遅いと思われていたとしたら、上記の理由に加えて開発言語の違いもあると思います。
Capture2TextはC++で開発されていますが、PCOTはC#なので普通に組むとどうしても速度に差が出てしまいます。
そういう意味では、もし今回の対応を施したとしても思った以上の速度改善は見込めないかも知れないです。
以上のことをご理解頂けると幸いです。
こちらこそはじめまして。
ご要望の件についてなんですが、元々PCOTのウィンドウを消しているのはキャプチャー画面起動中に翻訳表示画面を触れなくするのが目的でした。
なので対応するとしたらオプション項目を増やすのではなく、キャプチャー画面起動中は翻訳表示画面を触れなくするといった感じになるかな、と感じました。
これであれば、単一画面でもPCOTがフォーカスを奪うため、プロセスが最前面に表示される筈なのでどちらの場合でも邪魔にならないと思いますが、それでもよろしいですか?
はじめまして
私は2画面でサブの方にPCOTを置いて、メイン画面でゲームをしつつ利用しているのですが、画面を選択する時にPCOTのウィンドウが一旦消えるのが気になりました。
1画面だと大変ありがたい仕様ですが、サブに置いて一旦消えなくても良い場合このワンクッションは処理の遅延に繋がってないかなと感じたので、出来ればウィンドウを一旦非表示にする設定を切り替えられるようになったらいいなと思いました。
ショートカットの多ボタンマウス対応、前向きにご検討いただけるようで嬉しく思います。
PCOTのさらなる発展を楽しみに、引き続きこちらのページ、またTwitterの方も見させていただきます。
検証ありがとうございます。
なるほど、Capture2Textはその辺ちゃんと対応されているんですね。
すぐには無理ですが、一度対応してみようと思います。
なので、お手数ですが時々ここをチェックして頂けると幸いです。
もしTwitterをやっていたら、いつも近況報告をしているので、フォローして頂けるとこちらの動向が掴みやすいかもしれません。
迅速かつ丁寧なご説明ありがとうございます。
あくまで推測として、PCOT側の入力信号の優先順位や支配処理が原因なのでは?と理解いたしました。
ゲームパッドのボタンに割り当てて使う分には問題がないので「PCOT側ではショートカットと判断する前に
マウス入力として切り捨てられている」というご説明はとてもわかりやすく、素人の私でも理解できました。
もちろんPCOTと私が使用しているマウスとの個別の相性、またはマウス側の問題の可能性も考えられますが。
「Capture2Textではマウスからのショートカットに対応しているのでしょうか?」についてですが
Capture2Textではマウスのサイドボタンによるショートカット入力も問題なく使用できております。
具体的にはマウスの左側、右手持ちで親指が当たる側面部分にボタンが2つ並んでいるマウスなのですが、
そのボタンにショートカットキー(Capture2Textではhotkeys)を割り当てる、といった使い方です。
もし原因が推測通りなのであれば、誠に勝手ながらPCOTのさらなる発展を心より願っております。
こちらこそはじめまして。PCOTをご使用頂き、ありがとうございます。
ご指摘の件についてですが、当方がゲーミングマウスを所有していないため、全て推測になってしまうことを予めご留意願います。
推測される原因についてですが・・・
恐らく、システム側では最終的にショートカットとして認識していると思われますが、PCOT側ではショートカットと判断する前にマウス入力として切り捨てられているのかも知れません。
対応についてですが、もし私の推測が正しかった場合はPCOTの実装に問題があるので、PCOTを修正すれば対応できるかも知れませんが、先に書いた通り当方がゲーミングマウスを所有していないため、マウス入力の内容を精査できないんです・・・。
ちなみに、Capture2Textではマウスからのショートカットに対応しているのでしょうか?
もし試せるようでしたらご回答いただけると幸いです。
あまりお役に立てず申し訳ありません・・・。
はじめまして。
PCOT、英語が苦手ながら洋ゲーが好きな自分はとてもありがたく思いながら使わせていただいております。
ショートカットについて。ショートカットをゲームパッド+joytokeyで使用するには問題なく使えるのですが、
5ボタンマウスのサイドボタンに割り当てて使おうとしても無反応になります。(【フリー選択】が出来ない)
マウスのサイドボタンでショートカット(例えばCTRL+Fなど)が押されているのか、キーボードテストなどで
確認してみましたが、ショートカット(CTRL+F)は間違いなく押され、信号は送られているようでした。
つたない文章で状況を正確にお伝えできてるか不安ですが、この「マウスのサイドボタンでショートカットが
使えない(無反応)」の症状について、推測される原因や解決策などございましたらご教授いただければ幸いです。
※ゲームパッドやキーボードではまったく問題なく使わせていただいております。ありがとうございます。
PCOTを更新しました。
今回の更新も1点のみです。
Windows10以外のOSにも対応してみました。
Twitterの方でWin7の動作報告を頂けたので、それに合わせて修正してみました。
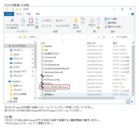
ご使用方法は以下の画像をご覧ください。
以上です。
これで動くといいなぁ・・・。
その疾さを体感せよ。
PCOTを更新しました!一度こういう痛い煽り文句付けてみたかったんですよねw
今回の更新は1点のみです。
PCOTが「Windows10 OCR」に対応しました!尚、以下の点を注意してご使用ください。
※以上を満たしていない場合、そもそもOCRエンジンの選択候補に出てきません。
尚、使用OCRエンジンの選択は「システム設定画面」から行えます。
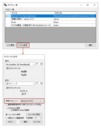
「参考画像」
Windows言語パック(英語)のインストール方法
コマンド:ms-settings:regionlanguage?activationSource=SMC-IA-4027670
以上です!動かないよーって方が居ましたら、お気軽にお問い合わせください。
PCOTを更新しました。
更新項目を以下に列挙します。
更新項目についての説明です。
【関係ないショートカット】
画像翻訳画面でSHIFT+ENTERなどを押すと、DeepLが反応しなくなったりしますがこれで今回の修正で直っている筈です。
【画像翻訳の画像ファイルの読取方法を変更】
時々、画像翻訳のファイルが削除できなかったので、画像ファイルの読取方法を変更しました。これで、プロセスがどうたら怒られずに画像ファイルを削除できる筈です。
【画像翻訳で大文字小文字が違うだけのプロセス起動時のSS失敗】
プロセス名が「Game」と「game」で違うプロセスだったとしても、ファイルパスは大文字小文字を区別しないため、同列と扱われますが、既存の画像ファイル名を文字列として扱うとエラーになってしまっていたため、画像翻訳については修正しました。(※他に同様の理由で不具合を起こす箇所があるかもしれません)
【キャプチャー画面起動時に対象プロセスのスレッドを停止】
今回の更新の目玉はこれです。地味ですがとても使える機能だと思います。
ゲームの種類によってはキャプチャー画面でフォーカスを奪ったとしてもポップアップが消えてしまったりするのを防止します・・・たぶん。
PCOTを更新しました。
今回の更新は大したことはありません。
更新項目としては、画像翻訳で←→キーの他にADキーで画像を切り替えられるように修正しました。あと、あまりにも拡大縮小の動きがもっさりしていたので、拡大/縮小の単位を若干上げました。
以上です。これくらいの更新だったら楽でいいなぁ・・・。
PCOTを更新しました。
久々の更新です。以下に更新内容を列挙します。
今回の更新について説明します。
【「翻訳結果をコピー」のチェック状態が記憶されない】
そのままです。ポカミスです・・・。直しました。
【スクロールキャプチャー機能追加】
洋ゲーで「キャラクターのセリフが勝手にスクロールして翻訳できない!」といった問題をなんとかしたくて追加した機能です。
先に注意事項を列挙しておきます。
<使用方法>
キャプチャーを終えた段階でキャプチャーされた画像が連結されて一つの画像になるよう処理します。
画像の連結が終わればそのままOCR読取を行い、読取結果を翻訳します。
更新は以上です。細かい不具合があるかも知れないので、もし変な動きをした場合はお知らせください。
以上です。めっちゃ疲れた・・・。
PCOTを更新しました。
今回は悲しいお知らせです・・・。
やはり翻訳精度を上げたせいか、無制限の使用が出来なくなってしまったようです・・・。
ただ、一度ブラウザと同じ精度で翻訳されるのに慣れてしまったせいか、どうしても元に戻すのが嫌だったので、弾かれた場合に元の無制限で使用できるバージョンに切り替えるように対応しました。
その際、使用している最中に突然アホな翻訳になってしまうので、今がどっちの状態かをステータス領域にて可視化させることにしました。
「参考画像」

※インターネット接続が切れている場合などは、プロセスの切断と同じカラー構成で「Google翻訳:無効」と表示されるようになっています。
ステータスの可視化は、プロセス選択時に一度ダミーの翻訳を投げてレスポンスの状態で表示を切り替えているので、プロセス選択はあまり頻繁に行わないよう推奨します。たかが一回、されど一回ですw
というわけで、今回はガッカリな更新になってしまいました・・・。
PCOTを更新しました。
以下に更新項目を列挙します。
更新項目について説明します。
【画像のローテーション表示】
左右キーで画像の表示をローテーションさせるように修正しました。
例)画像が3枚ある場合
「→キー」画像1→画像2→画像3→画像1
「←キー」画像1←画像3←画像2←画像1
【画像翻訳をショートカットで起動】
ショートカットが有効な状態で、翻訳表示画面起動中に「ベースキー」+「I」で画像翻訳画面を起動します。
☆注意☆
ショートカットの設定ファイルの内容が変わりますので、ショートカット設定画面を表示後、一度リセットして今回の更新を適用する必要があります。
【改行無視の修正】
「改行を無視」の実装により「対象通りに改行」と被らないように実装したつもりでしたが、色々とイベントが入り乱れて変なことになってたので修正しました。
【訳文で文字選択中に別のコントロールクリックするとエラー】
翻訳表示画面のサイズを変更できるようにした際に組み込んでしまったバグです。これで直っているハズ。
【辞書登録と名詞登録時の警告を削除】
原文を小文字化にチェックがあったとき、警告で大文字小文字が合ってないけど大丈夫ですか?みたいな警告を出してたんですが、今はもう不要なので削除しました。
なんか、普通にショートカットが実装できちゃったので今回の更新にまとめます。
お久しぶりです!すみません、結局実装しちゃいましたw
ただ、簡易コマンドも悪いものではないので残してあります。
たとえば、ゲーム上で何かキーボードのボタンが押されたら勝手に会話が進んじゃうようなゲームの場合は、ショートカットでキャプチャーを行うのが不可能なんですよね。(たとえアクティブじゃなくても)
後は、最近画像翻訳という機能も実装したので、そちらも使ってみてください。
詳しい説明を以下に貼っておきます。
画像翻訳説明1
画像翻訳説明2
作者の励みになりますので、また色々と感想とか要望とかくださいね!
あと、周りの人にも沢山広めてください!お願いします!
お久しぶりです。なんと見ていなかったうちにショートカットが実装されていたとは…。ゲームによっては簡易コマンドの切り替えがうまくいかないものがあったので、やっぱりショートカットもあればな…と思っていたのでとても嬉しいです。遅くなりましたが実装ありがとうございます!
PCOTを更新しました。
今回は一か所だけ更新しました。
「翻訳表示画面」の「原文を小文字化」のチェックボックスを廃止
代わりに、「改行を無視」のチェックボックスに変更
ちなみに、この「改行を無視」は領域単位でチェック状態を保存しています。(フリー選択を除く)
何がどう変わったかを一目で分かるようにまとめた画像を以下に貼りましたので参照してください。
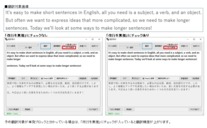
注:画像は英語で長い文章をつくるコツ!から拝借しました。
「原文を小文字化」を廃止した理由として、現在PCOTでは大文字小文字を自動的に判断して適宜変換するような処理を行っています。
例1)文章が全て大文字の場合は全て小文字に変換
処理前:I AM A PEN.
処理後:i am a pen.
例2)文章が強調表示などで単語単位で大文字の場合は小文字に変換(IやAなどの1文字だけ大文字の場合は除外)
処理前:I am a PEN.
処理後:I am a pen.
例3)単語単位で先頭以外の不自然な場所に大文字がある場合は単語単位で小文字に変換(OCR読取失敗対策)
処理前:TEST Test teSt tesT
処理後:test Test test test
前は上記の処理を行っていなかったため、一律「原文を小文字化」というチェックでごまかしていましたが、上記の処理をするようにしたので、もう要らないだろうということで廃止しました。
問題なさそうでよかったです。
こちらでも色々と試してますが、もし何かあった場合はお気軽にお問合せください。
素早い更新、ありがとうございます。
さっそく頂きました。
ためしたところ、問題なさそうです。
しばらく、これで試してみますね。